학회 논문 순서상으로 Tencent의 논문을 보려고 했었으나, 이전 포스트를 작성하면서 알게 되었던 논문이 인상적이어서 먼저 포스팅을 하기로 하였다.
이 논문의 저자 수가 자그마치 20명이다.
구글 연구원들이 학회에 참석하려면 공저자로라도 이름이 올라와야 된다는 규정이 있어서 팀원들이 모두 다 참석해서 가서 놀고 싶은 마음에 저자를 20명이나 했을리는 없을 것 같다. 저자명을 보니 굵직굵직한 이름들이 많이 포진되어 있다. 이전 논문에서도 그렇고 연구하는 방향이 일치하는 걸 보니 아마 mobile device 쪽의 음성인식 서비스를 강화하려는 움직임이 있는 듯하다.
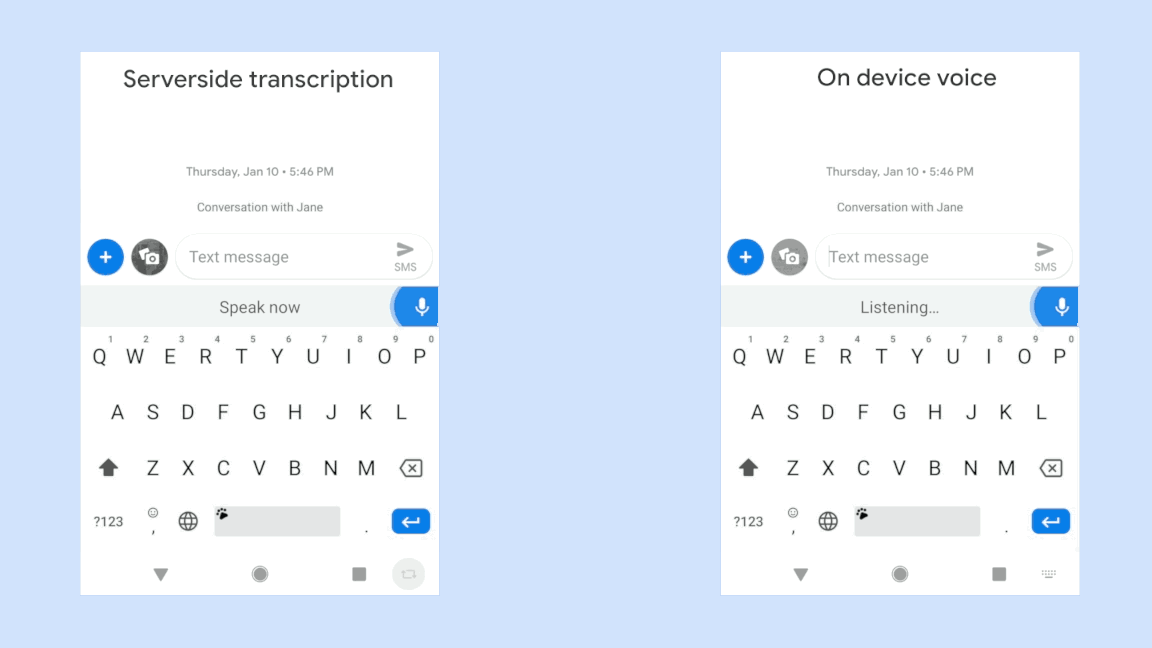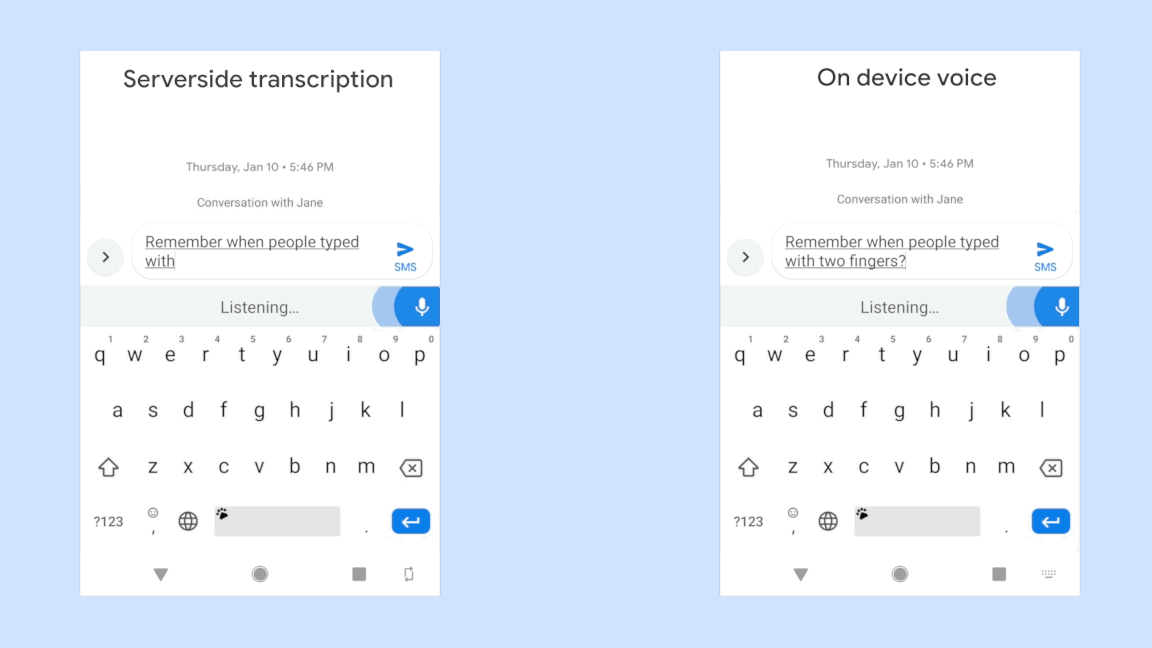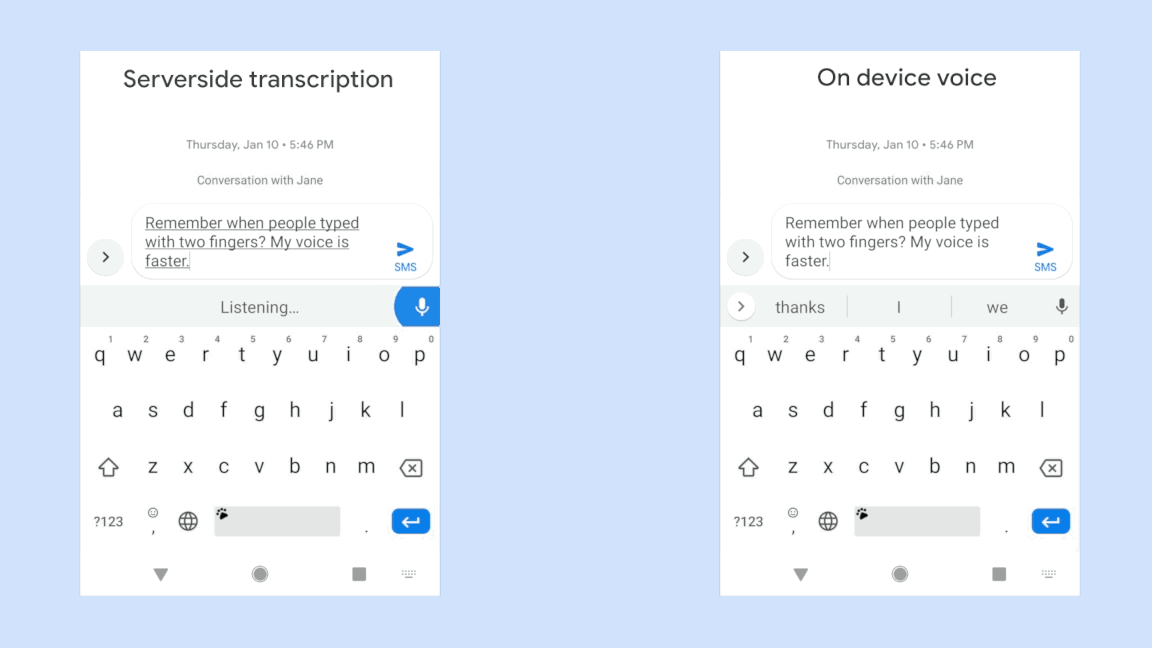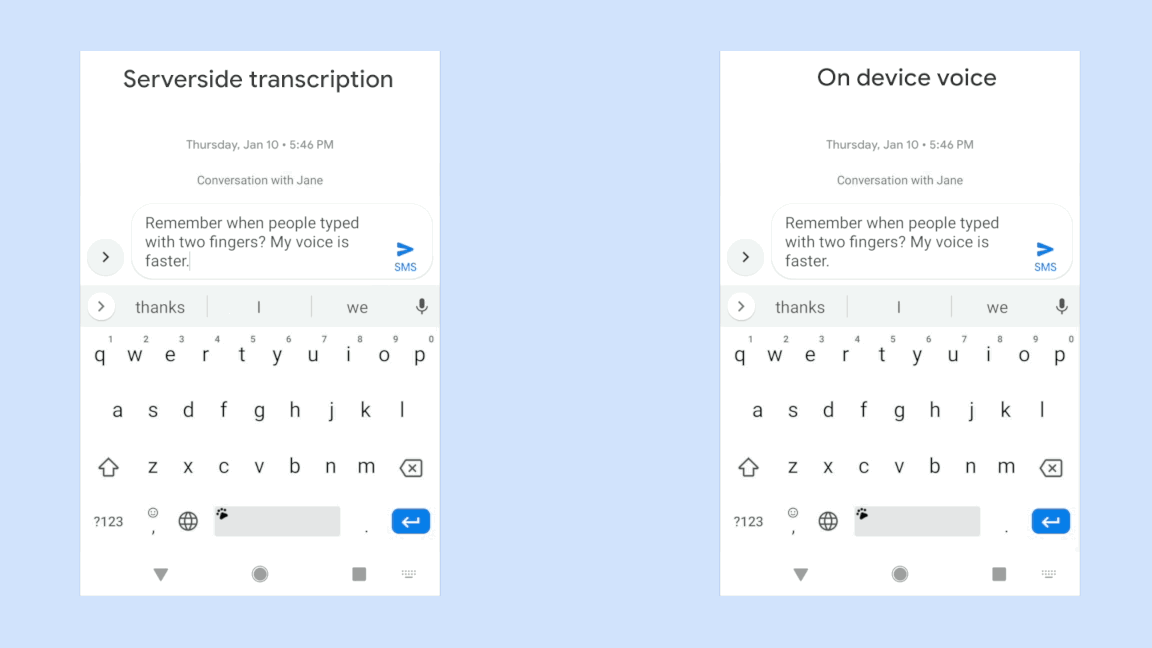
본 논문에서 mobile device에서 빠른 음성인식이 가능하도록 하기 위해서는 기존의 server-based service는 효율적이지 못함을 인정하고 latency를 줄이기 위해 on-device 형태의 시스템이 독립적으로 동작하는 형태여야 함을 말하고 있다.
전통적인 방식의 음성인식 서비스에 필요한 정보라 하면 전처리, AM, Lexicon, LM, WFST 같은 것들이 있을텐데 이런 녀석들이 복합적으로 엮여서 동작을 하려면 음성인식기 하나 돌리자고 mobile device의 resource를 다 잡아 먹을수도 있기에, 음성 전송에 의한 latency가 발생하더라도 어쩔수 없이 server-based service를 사용하는게 일반적이다.
하지만 세상이 바뀌었고, E2E 모델의 등장으로 인해 가볍게 decoding을 수행할 수 있는 모델들이 등장하고 있기에, 구글에서는 이런 E2E 모델을 통해 음성인식 속도를 높이기 위한 연구를 진행하고 있는 듯 하며 그 유력한 후보로 RNN-T 모델을 밀고 있는 듯 하다. 구글에서는 입력 sequence를 잔뜩 모아두고 attention을 해야하는 E2E 모델보다는 frame 단위로 output이 튀어나오고 이를 통해 beam search를 수행하여 인식결과를 뱉어낼 수 있는 RNN-T 모델이 on-device에 더 적합하다고 판단한 듯하다. 또한 이전 포스트에서 언급한 바와 같이 RNN-T 모델은 자체적으로 EPD 기능을 탑재할 수 있는 장점도 가지고 있기에 RNN-T를 더 밀어주는 분위기이다.
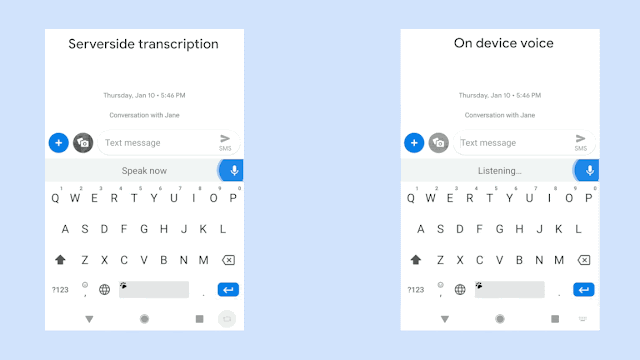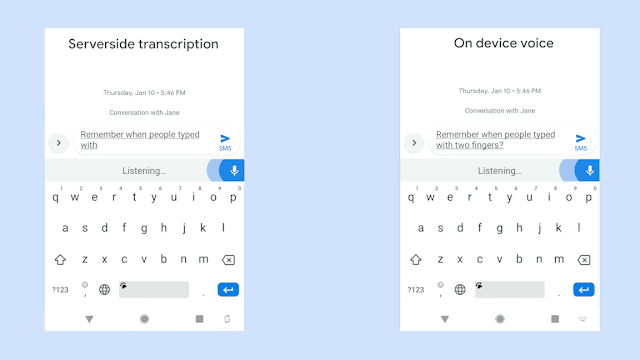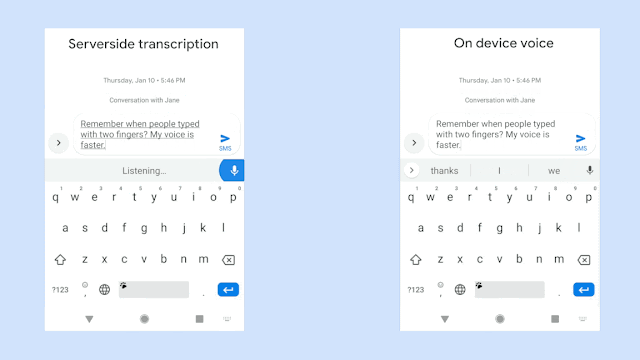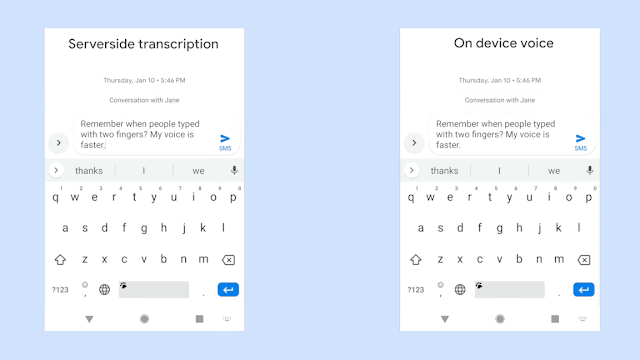
위 그림은 동일한 음성입력에 대해 구글에서 개발한 RNN-T기반의 on-device 음성시스템의 극명한 응답 속도의 향상을 보여주고 있다. 물론 자사의 sever-based system과의 비교이다. 동일한 인식성능을 보여주면서 저 정도의 속도차이라면 당연히 on-device system을 써야 하지만 사실 동일한 정확도를 만들어내는 것은 아직까지는 불가능한 일일 것이다. 위의 그림은 완전히 정제된 음성입력에 대한 속도차이만 보여주는 것일게다.
On-device system을 구축하기 위한 숙제를 논문에서 언급하고 있는데 그것은 다음과 같다.
먼저, 기존 시스템 만큼의 정확도가 보장되어야 하고, 그러는 중에 latency가 증가되지 않아야 하며,
다음으로, 언급한 것은 숙제라기 보단 on-device system의 특성을 활용하여 인식 성능을 극대화하기 위한 방안으로 device 사용자의 context를 고려할 수 있는 시스템이어야 한다는 것이다. 예를 들면 폰에 저장된 연락처와 음악 list같은 것을 인식할 수 있도록 구성되어야 한다는 것이다.
마지막으로, 뭔가 mobile device이다 보니 개개인이 아무렇게나 발성하는 "비주류"의 문장들도 찰떡같이 알아 들어야 한다는 것이다. 이를 테면 영어의 경우 "call two double four triple six five" 를 발성 그대로만 인식하는 것이 아닌 "call 244-6665"의 형태로 인식할 수 있어야 한다는 것이다.
여기까지는 어떤 on-device system의 의의와 방향성 같은 것에 대해서만 언급을 하였다.
이 논문에서는 이것을 위해 대충 RNN-T 모델을 썼다 정도가 아니라 이를 실현하기 위해 적용한 여러 practical한 기술들이 많이 정리되어 있다. 사실 학회 논문에서는 핵심 기술위주로만 설명하기에 이런 실용적인 기술에 대한 언급이 많이 없는 바, 알아두면 매우 소중한 것들이라 판단되어 다음 포스팅에서 각각의 방법들을 정리할 예정이다.



{kind=link}