E2E를 위한 훈련조건인 CTC를 활용한 Acoustic-to-Word Model에 관한 논문이다.
기존에 CTC는 연구자들의 번거로움을 덜어주기 위해 제안된 방법으로
궁극적으로 output에서 character 단위의 정보를 뱉어내게 하고 이를 특정한 search 알고리즘으로 인식된 단어열을 찾도록 하기 위한 것이었다.
하지만 실험을 해보니 인식 성능이 높지 않았고, 결국엔 vocabulary에 저장된 단어만을 decoding하던지 추가적으로 LM을 고려해야 기존 cross entropy기반으로 훈련된 모델의 인식율을 따라잡을 수 있는 정도였다.
인식율이 기대에 미치지 못하니,
연구자들은 character 대신에 단어를 뱉어내도록 하는 CTC를 연구했다.
그것이 Acoustic-to-Word(A2W) model이 되시겠다.
사실 Character 단위로 훈련을 하게 되면 잠정적으로 OOV 문제를 어느정도 커버할 수 있다는 장점이 있는데 A2W로 오면서 다시 OOV 문제를 생각해야 하는 상황이 발생하게 되고,
요새는 OOV를 검출할 수 있는 node를 추가하여 OOV를 발견하게 되면 character 단위의 정보를 통해 단어를 decoding 할 수 있도록 하는 방법을 사용하기도 한다.
이 경우 당연히 loss가 2개가 된다.
근데 이 A2W model은 output layer의 size가 커지다보니, DB의 size가 크면 좋은 성능을 발휘하지만, DB의 양이 적으면 E2E 모델의 고질적인 성능 저하의 문제가 발생한다.
A2W model의 경우, 각 output node가 하나의 단어를 대표하고 그에 따라 각 node에 연결된 weight를 word embedding으로 간주할 수 있게된다. 물론 실제 distributed representation과 같이 semantic 한 유사도를 가지고 표현되는지는 알수 없다.
이러한 가정하에 기존에는 output layer의 weight를 GloVe로 훈련된 word embedding을 사용하여 초기화한 뒤 A2W model을 훈련시키는 방법이 제안되었다.
본 논문에서는 acoustic 정보와는 괴리된 word embedding을 쓰는 것 대신에, acoustic 정보를 고려한 word embedding을 사용하여 A2W model을 초기화하는 방법을 제안한다.
기본적인 idea는 ICLR 2017에 발표된 "Multi-view recurrent neural acoustic word embedding"으로부터 착안하였다. 해당논문은 acoustic word의 각 단어간 차별성을 높여 이를 통해 음성인식이나 핵심어 검출에 활용하기 위한 방법을 제안한 것으로 embedding을 추출하기 위한 전체적인 구조는 본 논문과 유사하나 활용도 면에서는 다른 측면을 가지고 있다.
본 논문에서의 embedding을 추출하기 위한 전체적인 구조는 아래와 같다.
< Fig. 1 from this paper >
위 그림의 f(x)는 acoustic word embedding을 뽑기 위한 network 이며
g(c)는 acoustically-grounded word embedding, 즉 acoustic 정보를 반영한 word embedding 정보를 추출하기 위한 network가 되시겠다.
f(x) 그림에서 보는 바와 같이 BLSTM을 사용하고 있고,
acoustic word의 경계는 f(x) 출력 정보를 토대로 계산하는 것이 아닌,
기 훈련된 음향 모델을 통해 얻어진 forced alignment 정보를 사용했다고 한다.
이러한 단어간 경계 정보를 통해 acoustic word embedding은 정해진 구간의 hidden output의 평균을 통해 구하게 된다.
g(c)의 경우 text 정보를 통해 word embedding을 뽑아내는 network이다.
g(c)의 입력은 기 훈련된 character 단위의 embedding이며
이를 BLSTM으로 구성된 g(c)에 입력한다.
g(c)는 단어간 연결은 없으며 단어내 연결만이 존재한다.
각 단어별 embedding은 마지막 character 입력에 대한 BLSTM 출력을 사용한다.
최종적으로 f(x)의 출력과 g(c)의 출력은 선형변환된 형태로 얻어지게 되며 이 둘을 가깝게 하는 조건을 통해 각각의 network들이 훈련된다.
사실 위 그림은 각각의 network로부터 선형변환된 결과를 f(x), g(c)라고 명명했으나 편의상 f(x)와 g(c)를 각각의 network를 호칭하는 것으로 하였으며 그 이유는 최종적인 선형변환 행렬이 공유되는 형태이기 때문이다. 그렇기에 f(x)와 g(c)의 출력의 차원은 동일하다.
아래는 f(x)와 g(c)를 훈련하기 위한 훈련조건이다.
< Eq. 1 from this paper >
수식 자체는 margin을 고려한 일반적인 형태의 triplet loss이다.
Distance 함수 d(f(x), g(c))는 cosine distance를 사용하여 범위는 0부터 2까지의 범위를 가진다.
대괄호 뒤의 +는 hinge loss를 의미한다.
negative input은 mini-batch 내에서 최소 거리를 가지는 단어로 선정한다.
마진을 제외하고 생각하면 positive input의 거리가 negative input의 거리보다 클 경우 양수가 되고 이를 통해 gradient를 형성한다.
반대의 경우 음수가 되고 gradient를 형성되지 않는다.
양수의 마진 m을 고려하면 positive input의 거리가 negative input의 거리보다 -m만큼 작지 않으면 positive input의 거리는 가깝게 negative input의 거리는 더 멀게 하기 위한 gradient가 계속 생성된다.
Hinge loss는 마진 m과 결합하여 negative input의 거리가 충분히 멀어졌는데도 쓸데없이 멀게 만들기 위한 훈련을 방지하고자 하는 "don't care region" 을 형성한다.
위 수식에는 두개의 조건이 있는데
위의 조건은 negative input이 g(c)로부터 나오는 경우 g(c)를 f(xi)로부터 멀어지도록 하는 조건이며,
아래의 조건은 negative input이 f(x)로부터 나오는 경우 g(ci)로부터 f(x)를 멀어지도록 하는 조건이다.
이러한 조건으로 훈련이 완료되면, 각 단어별 선현변환된 g(c) 정보를 A2W model output layer의 초기 parameter로 사용하게 된다.
ICLR 2017 논문에서는 단어간 차별성이 높은 f(x)를 구하기 위한 목적이었다면, 본 논문에서는 A2W의 pretraining으로 f(x)와 g(c)를 훈련하여 사용한다는 데에 차이가 있다.
논문에서는 A2W model의 초기화를 위해 은닉층과 그 위의 선형 변환층까지 f(x)의 network 사용하였고, 출력층은 g(c)의 출력을 사용하였다.
자 그럼 이걸로 A2W를 훈련하기 위한 훈련 조건은 다음과 같다.
< Eq. 2 from this paper >
훈련 조건은 regularized 형태로 기본적인 CTC loss와 output layer의 parameter가 초기 설정된 word embedding으로부터 많이 멀어지지 않도록 하는 L2 loss로 구성되어 있다.
아래는 음성인식 실험결과이다.
< Table 3. from this paper >
실험 결과중 frozen은 OOV rescoring을 위해 output layer parameter를 고정한 결과이다. Intermediate size를 사용하여 성능 향상도가 크지는 않아보이지만, 그래도 안한것 보다는 낫다.
실험결과는 기 수행되어야 하는 사전작업의 양에 비추어 봤을때 향상도가 미미한 수준이라고 할 수 있겠다.
준비물:
1. Forced Alignment를 위한 음성인식 모델
2. Character-level embedding
3. 1, 2를 통한 acoustically-grounded word embedding 훈련
으윽.... 이걸 언제다;;;;;
논문에서 제안한 방법보다는
Triplet loss를 좀 더 색다른 방식으로 활용할 수 있다는 점에서 매력적인 방법이었다.
해당 논문의 main idea는 google brain의 "Weight uncertainty in neural networks"에서 가져왔다. 여기서는 기존의 deterministic한 parameter를 통해 network를 구성하는 방법 대신에 network parameter를 확률적으로 정의하고 이를 통해 훈련을 수행하는 Bayesian Network에 관한 내용을 포함하고 있다. Parameter의 확률적 정의 및 훈련 방법은 variational autoencoder의 방법에서 힌트를 얻은 듯 하다.
본 논문은 "Weight uncertainty in neural networks"의 방법을 단순히 E2E 음향모델에 적용한 것이며 아래와 같이 간단하게 정리할 수 있다.
- 각 single model parameter의 분포를 표현하기 위해 Gaussian 분포를 활용한다.
- 따라서 single model parameter를 확률적으로 표현하기 위한 mean, variance가 필요하다.
- 훈련 시에 variational autoencoder에서 활용하는 reparameterization 기법을 통해 model parameter의 sampling을 수행하고, 이를 forward propagation에 활용한다.
- 본 논문에서는 output layer와 bias를 제외한 나머지 LSTM parameter만을 확률적으로 표현하였다.
- Parameter의 uncertainty를 regularization 관점에서 활용하였기 때문에, test 시에는 mean 값만을 활용하여 forward propagation을 수행한다.
- Learning criterion은 CTC를 사용하였으며 추가적으로 weight prior를 고려하기 위해 L2 regularization도 같이 활용하였다.
실험결과
- WSJ와 CHiME4 DB에서 실험하였다.
- 단순히 해당 DB를 가지고 실험한 결과에서는 deterministic model과 probabilistic model간의 성능 차이는 보이지 않았다.
- WSJ로만 비교할 수 있어 따져보면 아주 살짝 좋아지지만 parameter의 수가 2배로 늘어났으니 deterministic model의 parameter의 수를 늘리기만 해도 다다를 수 있는 수치로 보인다.
- 효과를 발휘한 쪽은 weight pruning과 adaptation 쪽이었다.
- Weight pruning의 경우, deterministic model의 절대값 크기가 작은 parameter를 제거한 것과, probabilistic model에서의 mean과 variance의 비율인 SNR이 작은 paramter를 제거한 것을 비교한 결과, pruning된 parameter의 비율이 증가함에 따라 발생하는 성능 열화에 대한 저항성이 probabilistic model에서 더 강하게 나타나는 것을 보였다.
- Adaptation의 경우, SI model parameter를 기준으로 하는 L2 regularization 기반의 방법을 활용하였을 경우, adaptation의 효과가 더 크게 나타나는 것을 보였다.
고찰
- 실용적이기 보단 실험적인 논문이었다. 아직 특별한 유용함이 드러나는 것은 아니지만, Bayesian network을 음성분야에 적용하는 사례가 많지 않았기에 누구든 한번쯤은 시도해봤어야 하는 방법이 아니었을까 라는 생각이 들었다.
아직 볼 논문이 많다. 더욱 간단하게 정리할 필요가 있겠다.
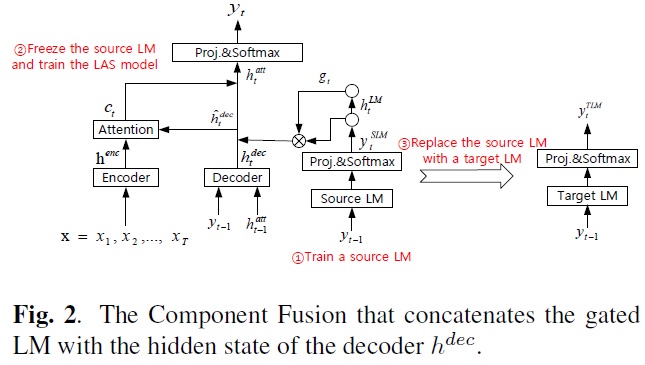
텐센트에서 나온 E2E 음성인식 시스템에 관한 논문이다. 오랜만에 보는 D. Yu의 논문.
원래 기존의 음성인식에서 AM과 LM은 따로 훈련되었고, 그걸 당연시 여겨왔다.
이것은 E2E 모델이 아무리 용가리 통뼈라고 해도 예외없이 적용되는 상황이었는데, 그래도 요새는 LM도 신경망으로 구축하는 시대이니 이 둘을 결합해야 하지 않겠느냐 하는 쪽으로 의견이 모아진 듯 하다. 동서양을 막론하고 새 술은 새 부대에 담고 싶은 모양이다.
변화의 시기에 보통 먼저 제안되는 방법은 예전의 방법을 지금의 조건에 맞추어 적용해보고 가능성을 가늠해보는 것이다. 그래서 최초로 제안된 방법이 shallow fusion이며 이는 AM과 LM의 score를 하나의 tunable parameter를 통해 가중합하는 방식이다.
다음으로 제안된 방법이 deep fusion이다. 이는 seq2seq 모델이 최초로 활용되었던 기계번역에서 제안된 방법으로, AM과 LM을 따로 훈련하고, LM의 output layer는 버린 후에, LM의 hidden layer 정보와 attention이 완료된 AM hidden 정보와 연결하여 최종 output layer의 입력으로 활용하는 것이다. Deep fusion에서는 output layer에서 AM과 LM이 결합되는 부분의 parameter를 적은 양의 훈련데이터를 통해서 훈련한다. 추가적으로 LM의 hidden layer 정보를 그대로 쓰는 것은 아니며 자기자신을 입력으로 하는 gating을 수행하여 필요한 정보를 뽑아내서 AM과 조합하는 것으로 되어 있다. 아, 그러고보니 gating에 해당하는 녀석도 fusion시 훈련이 이루어진다. Deep fusion에서는 AM과 LM의 몸통은 그대로 이며 머리 부분만 필요한 조건에 의해 훈련되는 과정을 거친다.
Cold fusion은 deep fusion의 고정된 몸통이 마음에 들지 않아 제안된 방법이다. 일반적인 LM은 범용 topic을 학습하였기 때문에 특정 domain의 성능을 극대화시키는데 활용하기에는 부족함이 있을 수 있다. Cold fusion에서는 LM으로는 부족한 domain dependent 정보를 AM 훈련 시 반영하는 훈련 방식을 취한다. 이를 위해 사전에 학습이 완료된 LM을 준비하고 deep fusion과 대동소이한 형태로 AM과 LM을 연결하고, AM에 해당하는 부분과 AM과 LM을 연결하는 부분의 parameter를 학습하는 방식을 취한다. 여기서 LM은 고정이다.
논문상에 각자의 fusion 방법에 대한 그림이 있으며 이들은 각각의 방식을 잘 나타내준다. 여기까지 언급한 fusion 기법들은 모두 AM과 LM을 잘 조합하여 음성인식율을 높이기 위한 방식이었다. AM과 LM이 잘 결합하면서 발생하는 한가지 단점은 이렇게 결합된 모델은 domain adaptation이 어려워지는 문제가 발생하게 된다. Adaptation을 위한 추가적인 훈련이 필요한 것이다.
이 논문에서는 fusion을 하는 데 있어 위에서 언급한 방법과는 조금 다른 방향성을 가지고 문제에 접근하고 있다. AM과 LM을 결합하는데 있어, in-domain에서의 음성인식률은 극대화 시키면서, 다른 domain에서의 adaptation도 쉽게 수행할 수 있도록 만들기 위해서는 AM과 LM의 동작이 완벽하게 분리된 형태로 학습이 되어야 한다고 말하고 있다. 다시 말하면 AM은 완벽하게 acoustic 특성만을 반영하기 위해 훈련되어야 하며, domain dependent한 특성은 LM을 통해서만 학습되어야 한다고 말하는 것이다.
이를 위해 이 논문에서는 cold fusion을 다른 방식으로 응용하고 있다. 우선 LM을 음성 corpus의 transcription을 이용하여 학습한 후 이를 고정한 채로 cold fusion의 방식을 통해 AM을 학습하게 되면, LM에서 이미 domain dependent information을 흡수한 상태이기 때문에 AM은 순수히 acoustic information만을 학습할 수 있다고 말하고 있다.
이렇게 훈련된 AM은 domain dependent한 요소가 최소화 되었기 때문에 좀 더 general한 음성을 표현하는 모델이 되었다 말할 수 있기 때문에, domain adaptation을 하는데 있어, 단순히 다른 분야의 text만을 통해 훈련된 LM을 사용하게 된다면 간단하게 해당 domain의 정보를 반영할 수 있게 된다고 말하고 있다. 아니면 LM만 적응하던가...
사실 계속 "말하고 있다"라는 표현을 쓰는 이유는 논문에서 저자들이 그러한 목적으로 모델을 구성하고 훈련을 하고 실험을 통해 그 효과를 입증할 뿐이며, 실제로 그렇게 동작해야만 하는 당위성은 수학적인 검증보단 단순한 썰을 통해서만 표현하고 있기 때문이다.
위의 그림이 논문상에서 제안한 방법이며 cold fusion과 크게 다르지 않다. 다만 gating을 수행하는 part에서 AM의 정보를 활용했었는데 deep fusion과 같이 LM의 정보만을 통해 gating을 수행하는 것으로 변경되었다.
첫번째 실험은 논문에서 목표하는 바대로 제안하는 방법이 out-of-domain에서 LM 교체를 통해 효과를 얻을 수 있겠는가에 대한 실험을 진행하였다.
여기서 보통은 AM과 LM의 정보를 concatenation할 때 attentional output과 결합을 하는데, 여기서는 decoder output과 결합을 한것에 대해 실험한 결과도 포함하였다.
뭐 in-domain 실험도 있지만 이건 생략한다.
Idea도 좋고 다 좋지만 먼가 좀 오타도 많고 성의 없이 쓴 논문을 보고 있노라면 별로 기분이 안좋다. 쓸데없는 짓을 한 것 같은 느낌이 강하게 들기 때문이다. 시간은 부족하고 봐야할 논문은 많은데 잘못 고른건가 싶은 생각이 들어서 그럴게다.
부디 이 포스팅이 쓸데없는 일이 아니었기를 빈다.
아니다. 쓸데없는 일은 아무것도 안하는 거다. 오늘도 나는 또 싸우는 구나.
이 논문에서는 구글에서 음성인식의 응답속도를 줄이기 위해 RNN-T model을 활용한 on-device 형태의 음성인식 시스템을 제안하였는데, 이 때 server-based system 대비 발생할 수 있는 성능 열화를 줄이기 위해 활용했던 알고리즘을 중심으로 논문을 기술하고 있다. 아래는 서론부에서 언급한 그 알고리즘들의 리스트가 되시겠다.
Layer normalization to stabilize training
Large batch size
Word-piece targets
Time-reduction layer to speed up training and inference
Network parameter quantization to reduce memory footprint and speech up computation
Shallow-fusion approach (AM + LM)
(사실 적어놓고 보니 그냥 E2E 모델에서 사용되는 방법인거 같다.) 이것들은 일반적인 음향모델을 좀 더 잘 훈련하기 위한 방법들로서 언급했다면, 근원적인 on-device향 모델의 한계로서 숫자음 인식 문제를 해결하기 위한 방법으로 다음을 언급했다.
TTS system으로 합성된 다양한 숫자음을 훈련에 활용
저런 방법들을 다 쓰니, 속도와 더불어 성능까지 올라간다고 하고 있다. 기존의 Embedded CTC와 비교해서 말이다.
우선 CTC나 RNN-T는 설명이 잘 된 논문들이 많으니 각설하고,
논문에서 언급한 내용들을 정리해 보니
<Model architecture>
Unidirectional LSTM 8층을 쌓고 Projected LSTM을 썼고
- LSTM output을 선형변환하여 차원 축소 Time-reduction layer (TRL)를 사용 했고
- 특정 layer의 출력을 N개씩 묶어 다음 layer로 보내는 방법으로 훈련과 inference 시간 단축, chain model에서와 같은 frame rate 조정을 통한 속도 향상)
- 여기서 TRL이 입력의 frame rate를 조절하는 것과는 다른 동작을 한다고 얘기하는데, 아무래도 frame rate는 정보가 삭제되는 것이고, TRL은 그래도 훈련상에 이런 decimation process가 고려되어 훈련이 이루어 지니 그걸 의미하는 것 같다.
- 아무래도 이 녀석은 encoder의 하위 layer에 적용이 되는 것이 상위 layer의 계산량을 줄이는 데 도움이 되기 때문에, 2번째 LSTM 위에 적용한 듯이 보인다.
<Training optimization>
Layer normalization을 사용했고
- layer별 출력을 batch가 아닌 해당 layer의 각 time step별 전체 node의 평균과 분산으로 whitening하는 방법으로, RNN 훈련 안정화를 위해 사용
Output node에 word-piece subword units을 사용했고
- Grapheme보다 나은 성능
Tensor processing units에 적합한 batched computation에 의한 FB (or BW) algorithm을 썼으며
<Efficient inference - Run-time optimization>
Prediction network의 중복 계산을 없애고 (50 ~ 60% prediction network 계산 절감)
Thread를 Prediction network, before and after TRL 3개로 나누어 asynchrony하게 처리하여 속도 절약 (single thread 대비 28% 속도 향상)
Device마다 저장된 사용자 별 데이터를 바탕으로 (이를테면 전화부, 노래, 앱, 위치 등등) 이를 고려하여 decoding시에 on-the-fly로 graph를 생성하고 음성인식을 수행
<Text normalization>
"navigate to two
twenty one b baker street" -> "navigate to 221b
baker street" 같은 decoding이 가능하도록 하게 만들기 위해, class-based LM을 활용하는 것과 유사한 방법으로 class에 대한 tag를 추가하여 이를 E2E model이 뱉어내도록 하고 이를 WFST로 올바른 written domain의 결과로 만들어 내는 방법을 사용하고 있다.
- 사실 이런 방법을 쓰기에는 데이터가 많지 않으므로, TTS를 활용하여 5백만 문장을 생성하여 이런 패턴의 문장을 학습하도록 하였다.
< table from this paper >
위 테이블에 논문에 언급된 방법들을 추가할때마다 인식 성능이 올라가는 것이 보인다. 뭐 이밖에도 TTS 데이터를 활용한 것과, RTF에 대한 결과들도 다 있지만, 여기선 생략하고 나중에 필요할 때 보는게 좋겠다.
중요한 것은 real time on-device 음성인식 시스템을 구축하기위해 얼마나 많은 기술들이 추가되어야 하는지 예상을 하며 준비해 나가야 한다는 것이다. 천하의 구글도 on-device 인식 시스템 개발을 위해 수년간 실험하고 노력한 결과로서 무언가를 내어 놓는데, 이것들이 단순히 방대한 양의 데이터를 활용한 정도의 결과로 치부해서는 안될 것이다.
물론 많은양의 데이터의 수집이 선행되어야 하는 것 맞는 말이다. 하지만 "그것이 전부다"라는 생각은 위험하다. 데이터 수집은 중요한 일이며 동시에 시간이 걸리는 일임을 인식하고 데이터를 모아가는 동시에 그것들을 요리할 수 있는 다방면의 기술 습득을 병행하지 않으면 힘들게 모은 데이터들이 무용지물 될 것이 뻔하기 때문이다.
학회 논문 순서상으로 Tencent의 논문을 보려고 했었으나, 이전 포스트를 작성하면서 알게 되었던 논문이 인상적이어서 먼저 포스팅을 하기로 하였다.
이 논문의 저자 수가 자그마치 20명이다.
구글 연구원들이 학회에 참석하려면 공저자로라도 이름이 올라와야 된다는 규정이 있어서 팀원들이 모두 다 참석해서 가서 놀고 싶은 마음에 저자를 20명이나 했을리는 없을 것 같다. 저자명을 보니 굵직굵직한 이름들이 많이 포진되어 있다. 이전 논문에서도 그렇고 연구하는 방향이 일치하는 걸 보니 아마 mobile device 쪽의 음성인식 서비스를 강화하려는 움직임이 있는 듯하다.
본 논문에서 mobile device에서 빠른 음성인식이 가능하도록 하기 위해서는 기존의 server-based service는 효율적이지 못함을 인정하고 latency를 줄이기 위해 on-device 형태의 시스템이 독립적으로 동작하는 형태여야 함을 말하고 있다.
전통적인 방식의 음성인식 서비스에 필요한 정보라 하면 전처리, AM, Lexicon, LM, WFST 같은 것들이 있을텐데 이런 녀석들이 복합적으로 엮여서 동작을 하려면 음성인식기 하나 돌리자고 mobile device의 resource를 다 잡아 먹을수도 있기에, 음성 전송에 의한 latency가 발생하더라도 어쩔수 없이 server-based service를 사용하는게 일반적이다.
하지만 세상이 바뀌었고, E2E 모델의 등장으로 인해 가볍게 decoding을 수행할 수 있는 모델들이 등장하고 있기에, 구글에서는 이런 E2E 모델을 통해 음성인식 속도를 높이기 위한 연구를 진행하고 있는 듯 하며 그 유력한 후보로 RNN-T 모델을 밀고 있는 듯 하다. 구글에서는 입력 sequence를 잔뜩 모아두고 attention을 해야하는 E2E 모델보다는 frame 단위로 output이 튀어나오고 이를 통해 beam search를 수행하여 인식결과를 뱉어낼 수 있는 RNN-T 모델이 on-device에 더 적합하다고 판단한 듯하다. 또한 이전 포스트에서 언급한 바와 같이 RNN-T 모델은 자체적으로 EPD 기능을 탑재할 수 있는 장점도 가지고 있기에 RNN-T를 더 밀어주는 분위기이다.
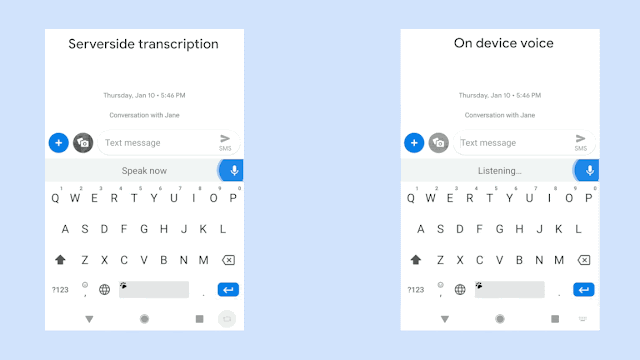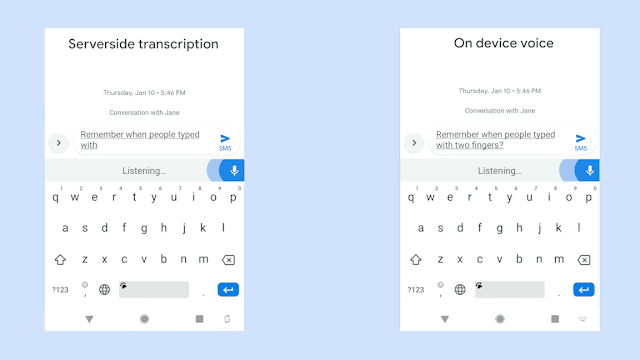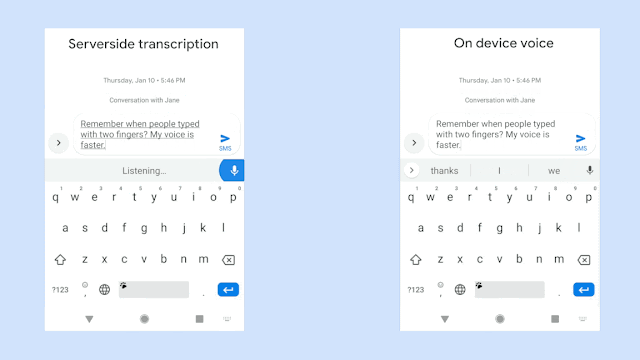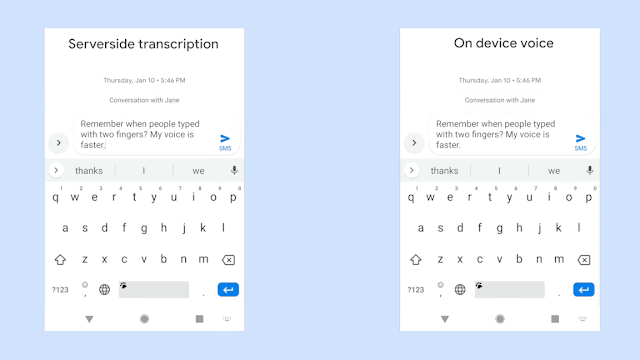
<figure from "https://ai.googleblog.com/2019/03/an-all-neural-on-device-speech.html">
위 그림은 동일한 음성입력에 대해 구글에서 개발한 RNN-T기반의 on-device 음성시스템의 극명한 응답 속도의 향상을 보여주고 있다. 물론 자사의 sever-based system과의 비교이다. 동일한 인식성능을 보여주면서 저 정도의 속도차이라면 당연히 on-device system을 써야 하지만 사실 동일한 정확도를 만들어내는 것은 아직까지는 불가능한 일일 것이다. 위의 그림은 완전히 정제된 음성입력에 대한 속도차이만 보여주는 것일게다.
On-device system을 구축하기 위한 숙제를 논문에서 언급하고 있는데 그것은 다음과 같다.
먼저, 기존 시스템 만큼의 정확도가 보장되어야 하고, 그러는 중에 latency가 증가되지 않아야 하며,
다음으로, 언급한 것은 숙제라기 보단 on-device system의 특성을 활용하여 인식 성능을 극대화하기 위한 방안으로 device 사용자의 context를 고려할 수 있는 시스템이어야 한다는 것이다. 예를 들면 폰에 저장된 연락처와 음악 list같은 것을 인식할 수 있도록 구성되어야 한다는 것이다.
마지막으로, 뭔가 mobile device이다 보니 개개인이 아무렇게나 발성하는 "비주류"의 문장들도 찰떡같이 알아 들어야 한다는 것이다. 이를 테면 영어의 경우 "call two double four triple six five" 를 발성 그대로만 인식하는 것이 아닌 "call 244-6665"의 형태로 인식할 수 있어야 한다는 것이다.
여기까지는 어떤 on-device system의 의의와 방향성 같은 것에 대해서만 언급을 하였다.
이 논문에서는 이것을 위해 대충 RNN-T 모델을 썼다 정도가 아니라 이를 실현하기 위해 적용한 여러 practical한 기술들이 많이 정리되어 있다. 사실 학회 논문에서는 핵심 기술위주로만 설명하기에 이런 실용적인 기술에 대한 언급이 많이 없는 바, 알아두면 매우 소중한 것들이라 판단되어 다음 포스팅에서 각각의 방법들을 정리할 예정이다.
이 논문 이전에는 아래 그림과 같이 frame 단위로 음성, 최초 silence, 중간 silence, 마지막 silence를 찾도록 하여 마지막 silence가 보이면 마이크 입력을 끝내고 음성인식 절차로 들어가도록 하는 방법을 취하여 EPD에 필요한 latency를 줄일 수 있는 방법을 제안했었다. 이 녀석의 이름을 end-of-query (EOQ) model이라고 불렀다.
<*Figure from "Endpoint detection using grid long short-term memory networks for streaming speech recognition">
본 논문에서는 앞서 언급한 EOQ 모델이 음성입력에만 의존하여 end point를 찾아내는 것을 단점으로 들었다. 또한 이후에 진행되는 음성인식 절차와 분리되어 end point를 찾아내는 것을 두번째 단점으로 들었다. 같은 말이다. 음성에만 의존적이라 음성인식결과를 반영할 수 없는 거니까.
여하튼, 이 논문에서는 이전과 다르게 streaming 입력으로부터 음성인식과 EPD를 동시에 수행할 수 있는 방법을 제안하였다. 준비물은 RNN-T 음향모델과 문장의 끝을 나타내는 special character </s>를 추가하여 훈련을 수행한 것이다.
여기서 왜 attention 기반의 E2E 모델을 사용하지 않았는지 의문이었는데, 그것에 대한 이유는 논문에 나타나있다. Attention 기반의 E2E 모델에서는 decoding을 끝내기 위한 character <eos>가 이미 있기는 하지만 그것은 encoder와 decoder에서 생성하는 sequence가 다르기 때문에 사용되는 것으로 EPD를 위해 사용하기에는 부적합하다.
또한 Attention 기법 자체가 고정된 전체 입력 sequence를 decoder의 time step마다 가중합하는 방식을 취하기 때문에 모델 자체도 EPD와는 궁합이 좋지가 못하다.
RNN-T의 경우 CTC기반의 E2E 모델로서 frame 단위의 output을 생성하기 때문에 각 frame time step 별로 탐색 beam을 만들어 가면서 적은 latency로 또는 on-the-fly로 end point를 찾을 수 있게 되는 것이다.
다만 주의 할 것은 중간에 </s>가 튀어 나오는 것은 단순히 character 하나가 잘못 decoding 되는 것과는 무게감이 다르다. (문장 뒤쪽이 전부 날아가는 것이다.) 따라서 search beam을 구성하는데 아래와 같은 constraint를 둔다.
논문에서는 문장 끝을 나타내는 token </s>에 대한 사후 확률값이 \(\beta\)를 넘을 때에만 search beam에 포함시키는 조건을 두었다. 추가로 \(\alpha\)를 1보다 크게 설정할수 있도록 하여 왠만해서는 </s>가 search beam에 포함될 수 없도록 조치하였다.
결과를 보니 제안하는 방법에서 latency에 따른 오류율이 현전히 줄어듦을 보여주고 있다. 이 논문을 보기 전에 나는 CTC기반의 모델이 단지 attention기반 E2E 모델에 다다르는 징검다리 역할에 불과하다고 생각했는데, 이런 식의 장점이 있는 줄은 몰랐다. 역시 뭐든 끝까지 파는 놈이 뭔가를 건지는가 싶다.
대충 정리하고 싶었는데, 대충 정리가 안된다. 큰일이다. 이렇게 오래 걸리면 안되는데...
Attention을 활용한 Sequence-to-Sequence(S2S) 모델은 기계번역쪽에서 제안된 모델이고
이걸 음성인식에 적용한게 요새의 End-to-End(E2E) 음향모델이다.
기계 번역쪽에는 attention을 LSTM 구조에서 활용 했을 때 훈련시 발생하는 latency가 맘에 들지 않아 self-attention 기법을 활용하는 구조인 "The Transformer"를 제안했고
sequential data modeling을 위한 구조는 필요없고 필요한건 오직 하나 attention만 있으면 된다는 의미의 공격적인 논문의 제목 "Attention is all you need"가 나왔다.
본 논문의 저자들은 요 Attention is all you need가 완전 cool하다고 생각했는지 어떻게든 이 title을 hommage 하고 싶었던 것 같다.
논문의 내용은 기존의 E2E 음향모델이 character를 decoding하도록 모델링 되었는데 다국어 음성인식을 하는데 있어서 각 나라별 character를 따로 두고 훈련하느니 그냥 각 character의 UTF-8 인코딩 정보를 디코딩 할 수 있도록 하여 언어 확장성을 높이려고 한 논문이 되시겠다.
논문에서는 8 bits 정보를 decoding하기 위해 \(2^8=256\) 개의 노드를 사용하는 softmax output layer를 구성하였다.
위 테이블에 영어와 스페인어는 성능향상이 없었으나, 한국어와 일본어의 경우 성능향상이 있었는데, 영어와 스페인어의 경우 하나의 문자가 하나의 캐릭터로 표현이 되지만, 한국어와 일본어의 경우 하나의 문자가 여러 캐릭터의 조합으로 이루어지기 때문에, 문자 단위의 output node를 구성하면 수천개의 output node가 필요한 것을 성능향상의 이유로 들고 있다.
Unicode를 사용하게 되면 수천개의 label을 사용하면서 필연적으로 발생하는 label sparsity가 줄어 들어 음향 모델 학습을 더 잘하게 되고 이런 이유로 음성인식 성능이 향상되었다고 말하고 있다.













{kind=link}




